
On September 27th 2021, AWS announced that you could now integrate Network Load Balancers (NLB) and Application Load Balancers (ALB) directly. This is a profound change to the ways that you can arrange your load balancer topology and will enable many AWS customers to cut much of the complexity in their architecture.
In this post I want to talk about what this looks like and what this means for two major use-cases.

Running services behind an Application Load Balancer (ALB) is the de facto standard for Layer 7 container and EC2 workloads on AWS, but it has some design constraints which may mean you have to get creative with your network plumbing. Specifically, an ALB cannot be directly associated with static IP addresses, and the IP addresses of an ALB will change unpredictably.
This can be an architectural pain point when using AWS PrivateLink. The SaaS companies we’ve worked with use PrivateLink in different ways. Some expose their services to certain customers without sending that traffic over the public internet. The problem with static IP addresses also presents itself when securing network communications from a customer’s on-prem servers to services deployed on an AWS estate.
There are ways to mitigate that pain, but before this recent announcement, those mitigations would feel like you’re either getting spanked for extra network traffic costs, or you are suddenly adding a whole bunch of DIY widgets to your infrastructure.
The Feature - a new kind of Target Group
Fast-forward to the AWS announcement - the AWS blog revealed that there was a new kind of Target Group that has the ability to track an ALB’s IP addresses. This is available alongside the other kinds of Target Group which cover tracking IP addresses/ports, Lambda functions and EC2 Instances.
To be updated in a reliable way, I would assume that the new Target Group hooks into internal events that the ALB generates when scaling operations occur (which are sadly not available via EventBridge) and that means those events cause the Target Group to update with minimal latency.
Now then, let’s have a look at what happens to those use-cases when we introduce this new Target Group.
Use-Case #1 - Egress through a firewall
Before…
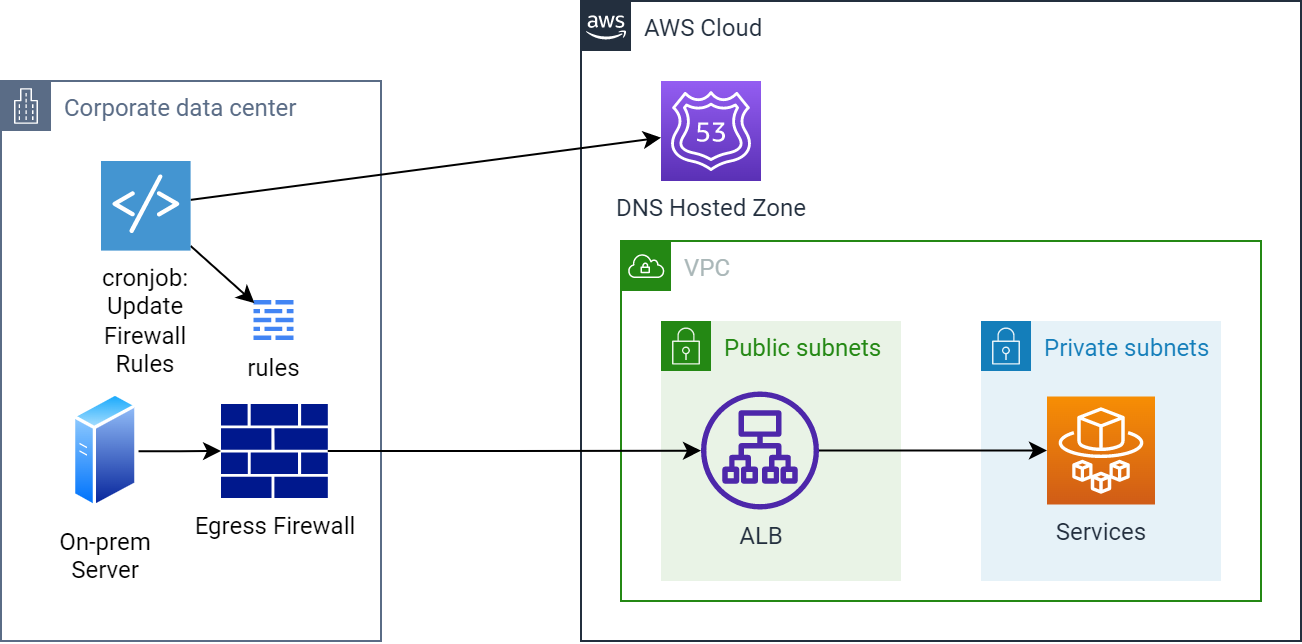
Egress through an on-prem firewall to an ALB including firewall rule update mechanism
Here you can see a scheduled cron job that sits in the on-prem network. The script could use the dig tool to fetch the DNS records for your service in AWS and ensure that any egress firewall entries for it are synchronised to the results. This will hopefully have small enough latency that outbound connections from on-prem are not interrupted by an IP address change.
If you have a system like the above that locks down its egress through a firewall, creating an allow-list of IP addresses to an ALB is problematic as the addresses for the ALB will shift over time.
To get around this you could potentially do one of the following:
- use AWS Global Accelerator to get static IP addresses for an ALB, incurring extra cost for traffic based on geographic location
- create a scheduled process that periodically updates your firewall using the DNS results for the load balancer
Neither of these are ideal as they involve either paying more for your load balancer traffic or having an extra moving part that will hopefully keep your firewall in sync with your actual infrastructure.
After…
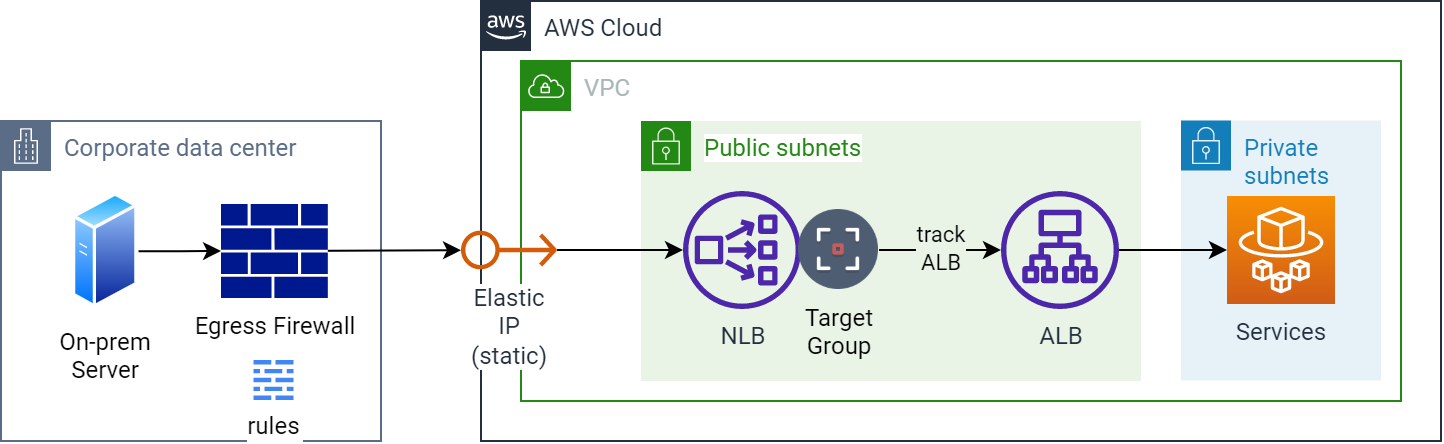
Egress through an on-prem firewall using an NLB for a static IP address
As you should be able to tell from the diagram, we have dispensed with the cron job-driven mechanism that scans for changes to the DNS entries for the load balancer. An NLB has been added in front of the ALB (which could be moved to the private subnets), and an Elastic IP has been added and associated with it. Now that the NLB is tracking the ALB’s IP addresses, the firewall rules need only have the static Elastic IP address(es) defined, removing a great deal of added complexity.
I think it’s fair to say that most infrastructure or InfoSec engineers would be much happier now that the firewall doesn’t have to be modified on-the-fly by an external process.
Use-Case #2 - PrivateLink
Before…
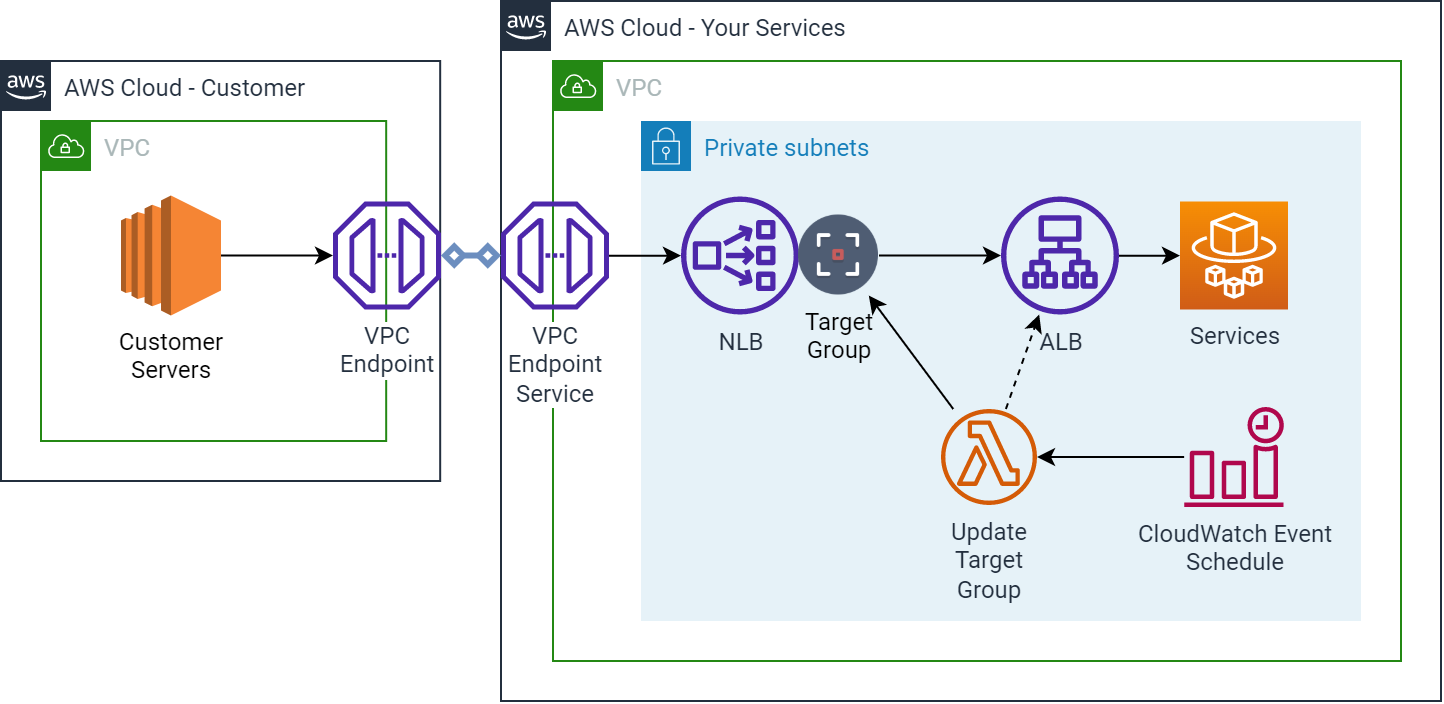
Ingress from a VPC Endpoint Service including Target Group update mechanism
The diagram shows a solution suggested by an AWS Blog that uses a Lambda function on a scheduled run from CloudWatch Events. The Lambda function works out the latest IP addresses for the ALB and updates the NLB Target Group to keep it updated.
Another example is when you want to make your services accessible to another AWS VPC or Account from a VPC Endpoint Service. The problem here is that an NLB is required by the VPC Endpoint Service, and prior to this feature being released, it was not possible to connect to the ALB without having some kind of mechanism that updated the target of the NLB dynamically.
This left you with only a couple of options:
- create a scheduled process (e.g. a Lambda) which periodically scans for changes to the DNS or the Elastic Network Interfaces that the ALB is associated with, and updates the NLB Target Group with those IP addresses
- set up EC2 instances as a reverse proxy onto your ALB, resolved using DNS name.
Again - extra moving parts, brittleness, and added complexity.
After…
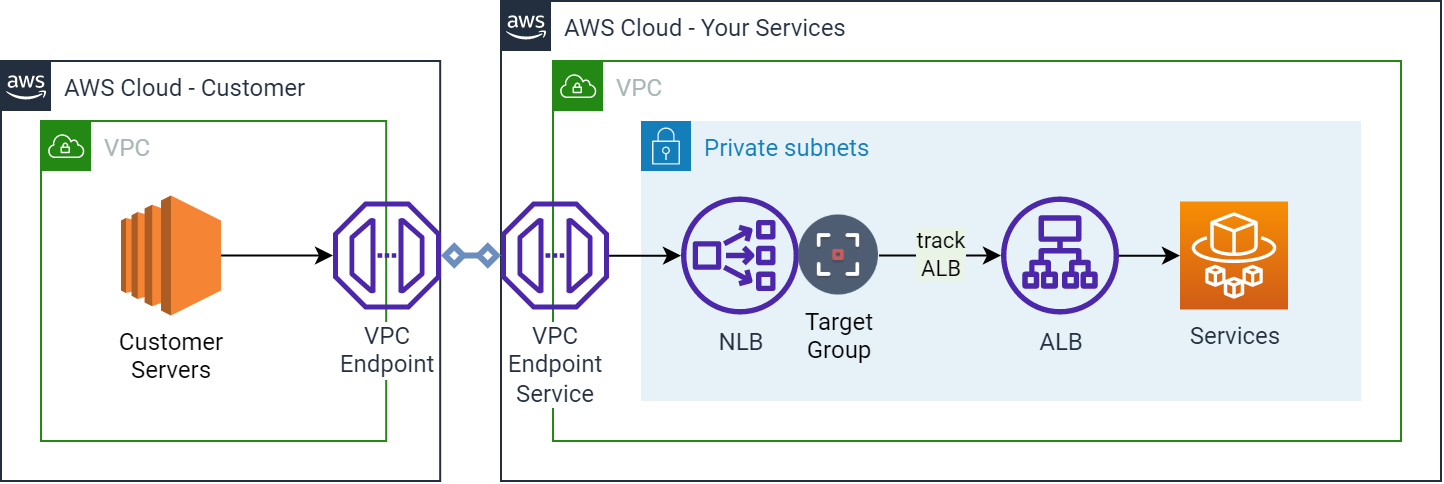
Ingress from a VPC Endpoint Service that tracks the ALB
Similarly to Use-Case #1, this diagram now shows a solution which has had the CloudWatch Event/scheduled Lambda removed. The Target Group on the NLB tracks the ALB’s address changes, faster, more directly and reliably than any external scanning process ever could.
In this case, we are keeping the original NLB that is a requirement for PrivateLink. The only additional change is the new NLB Target Group that is linked to the ALB.
Wrapping up
I hope that it is clear from how I’ve described the way that these use-cases can be tackled differently, that this new feature can help reduce complexity in many AWS networking solutions. Also, I think it’s reassuring that AWS are continuing to iterate on features for these kinds of resources, allowing customer architecture to iterate too.
For those on a budget it may seem like a drag to add another load balancer in front of your services. However, I would argue that for when a static IP address is needed for services behind an ALB, or for when using PrivateLink for the same kind of services, simplifying your solution is much more valuable.
Designing effective systems security for your SaaS business can feel like a distraction from delivering customer value. Book a security review today.
This blog is written exclusively by The Scale Factory team. We do not accept external contributions.